

Kontingenční tabulky
Kontingenční tabulky představují velmi jednoduchou a rychlou možnost pro analýzu dat. Pod touto analýzou si můžeme představit souhrn dat s využitím jedné z 11 základních funkcí plus možnosti pro různé zobrazení těchto souhrnů.
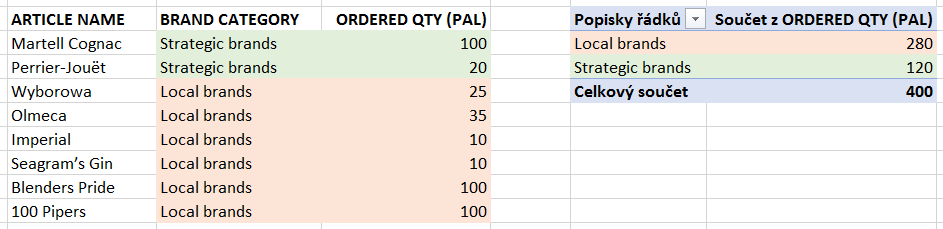
Struktura dat pro snadnou analýzu
Existuje několik pravidel, které je nutné dodržet, aby bylo možné ze zdroje dat vytvořit kontingěnční tabulku, a zároveň existuje několik doporučení, jejichž dodržování vede např. ke snadnější práci s KT. Nejzásadnější požadavek na zdrojová data je spjat s jejich strukturou. Z tabulky s maticovou strukturou není možné vytvářet souhrny pomocí kontingenční tabulky, proto je potřeba tabulku ztransponovat do 2D struktury, což mnohdy neznamená použít jednoduchý příkaz pro transponování tabulky, ale zdlouhavě tabulku do této podoby upravovat.

Doporučení a požadavky na zdroj dat
Požadavky
- 2d struktura dat
- každý sloupec ve zdroji dat musí mít záhlaví
Doporučení
- vyhnout se prázdným polím
- vyhnout se chybám ve zdroji (výpočetní chyby, např. #není_k_dispozici, #odkaz!)
- vyhnout se nekonzistenci dat (různé hodnoty v datových sloupcích)
Jak fungují kontingenční tabulky
Kontingenční tabulky jsou vždy postaveny na nějakém zdroji dat. Nejsou k němu však připojeny přímo. Mezi zdrojem dat a kontingenční tabulkou je ještě mezipaměť kontingenční tabulky (Pivot Cache). Smyslem Pivot Cache je snížení nároků na systémové požadavky. Pokud vytváříme více kontingenčních tabulek ze stejného zdroje dat, tak se zdrojová data uloží do této mezipaměti a odtud jsou načítány do připojených kontingenčních tabulek. Pro každou tabulku tedy nevzniká nová mezipaměť, pouze pro ty kontingenční tabulky, které jsou postaveny na novém zdroji dat.
